一. 概述
在当今快速发展的信息技术领域,文本生成技术已成为人工智能领域的一个重要分支。它不仅涉及到自然语言处理(NLP)的多个子领域,如语言模型、机器翻译和文本摘要,而且对于提高用户体验和自动化内容创作具有重要意义。因此,对文本生成系统的性能进行评估是至关重要的,下面本文将会介绍一些常见的文本生成任务评价指标及代码实现。
二. 常见指标及代码实现
1. BLEU指标
(1)介绍
BLEU(bilingual evaluation understudy),首次出现在IBM发表的一篇名为BLEU: a Method for Automatic Evaluation of Machine Translation的论文中,详情可见参考文献P02-1040.pdf (aclanthology.org)。BLEU的中文翻译为双语评估替补,所谓替补可以理解为通过机器代替人类进行翻译,所以这项指标的含义就是评估机器翻译结果的质量,但是这项指标有时也会被用在除机器翻译之外的文本生成任务。
(2)计算过程
公式如下所示:
| 符号 | 解释 |
|---|---|
| c | candidate 机器译文的文本长度 |
| r | reference 标准译文的文本长度 |
| BP | brevity penalty 惩罚项 |
| N | n-gram的数值,一般可以取1,2,3,4 |
| $w_n$ | 各个n-gram的权重 |
| $p_n$ | modified precision score |
(3)代码实现
为了简单起见,这里使用nltk提供的计算方式来进行计算,有兴趣的小伙伴可以阅读对应的源码以获得更深入的了解:
from nltk.translate.bleu_score import sentence_bleu
def cal_bleu(reference, candidate, weights):
"""
:param candidate: 机器译文
:param reference: 参考译文
:param weights: n-gram的权重
:return: bleu score
"""
score = sentence_bleu(reference, candidate, weights=weights)
return score
if __name__ == "__main__":
# 参考译文
reference = [['It', 'is', 'sunny', 'today', 'so', 'many', 'people', 'have', 'a', 'picnic']]
# 机器译文
candidate = ['It', 'is', 'sunny', 'today', 'so', 'many', 'people', 'have', 'a']
# 各个n-gram的权重
weights=(0.25, 0.25, 0.25, 0.25)
# 计算bleu score
score = cal_bleu(reference, candidate, weights)
print(score)
2. METEOR指标
(1)介绍
在自然语言处理(NLP)中,METEOR(Metric for Evaluation of Translation with Explicit ORdering)是一种被广泛使用的用于评估机器翻译质量的指标,可以计算生成文本和参考文本之间的相似程度。由Banerjee和Lavie于2005年提出,METEOR旨在克服BLEU等传统翻译评估指标的一些局限性。以下是METEOR的几个关键特点和优势:
- 词形匹配(Word Form Matching):METEOR不仅仅依赖于词的精确匹配,还考虑了词形变化。例如,它会将“run”和“running”视为相关词,这有助于更准确地评估翻译的语言多样性和自然性。
- 同义词匹配(Synonym Matching):通过利用同义词词典(如WordNet),METEOR能够识别并匹配同义词,从而提高评估的包容性。例如,将“big”和“large”视为匹配词。
- 词序权重(Order Penalty):METEOR对词序进行惩罚,确保翻译的词序接近参考翻译。这使得它比BLEU更能捕捉到翻译的语言流畅性。
- 基于片段的评估(Chunk-Based Evaluation):METEOR基于有意义的片段(chunks)进行评估,而不是单独的词。这有助于更好地评估句子结构和连贯性。
(2)计算过程
| 符号 | 机器翻译中常见取值 |
|---|---|
| $\alpha$ | 3 |
| $\theta$ | 0.5 |
| $\gamma$ | 3 |
- 首先计算 unigram 情况下的准确率P和召回率R,得到调和均值F值:
- 然后再计算惩罚因子
- 最后计算出METEOR值
(3)代码实现
from nltk.translate.meteor_score import meteor_score
def cal_meteor(reference, candidate):
"""
:param candidate: 机器译文
:param reference: 参考译文
:return: meteor score
"""
score = meteor_score(reference, candidate)
return score
if __name__ == "__main__":
# 参考译文
reference = [['It', 'is', 'sunny', 'today', 'so', 'many', 'people', 'have', 'a', 'picnic']]
# 机器译文
candidate = ['It', 'is', 'sunny', 'today', 'so', 'many', 'people', 'have', 'a']
# 计算meteor score
score = cal_meteor(reference, candidate)
print(score)3. ROUGE
(1)介绍
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)算法由 Chin-Yew Lin 在 2004 年的论文《ROUGE: A Package for Automatic Evaluation of Summaries》中提出。与 BLEU类似,通过统计生成的摘要与参考摘要集合之间重叠的基本单元的数目来评估摘要的质量,该方法已成为自动文摘系统评价的主流方法。在前面我们介绍过BLEU分数,但是BLEU关注的是生成序列中的单个词或短语是否在参考序列中是否出现,这可能会带来一个问题:生成的序列也许是通顺的,但是其实和原文相关度不大(形象来说就是胡乱翻译),那么ROUGE就是这个问题的一种解决方案:ROUGR算法能够衡量参考序列中的单个词或短语是否在生成序列中出现,即相比BLEU关注生成序列的准确性而言更加关注生成序列的召回率。
以下内容基于文本摘要生成任务进行介绍。
(2)计算过程
这里我们介绍两种常见的ROUGE指标,分别为ROUGE-N与ROUGE-L,如下所示:
- ROUGE-N (将BLEU的精确率改为召回率)
- ROUGE-L (将BLEU的n-gram改为公共子序列(LCS))
a. ROUGE-N
计算公式为:
分子就是生成摘要与参考摘要相匹配的$n-gram$个数,分母就是参考摘要中所有的$n-gram$个数。
符号说明:
- $Ref\ Summaries$ 表示参考摘要集合
- $Count_{match}(n-gram)$ 表示生成的摘要和参考摘要中同时出现的 $n-gram$的个数
- $Count(n-gram)$则表示参考摘要中出现的$n-gram$个数。
b. ROUGE-L
$LCS(X,Y)$是$X$,$Y$的最长公共子序列的长度,$m$和$n$分别是参考摘要和生成摘要的词汇数量,则我们可以知道$R_{lcs}$,$P_{lcs}$ 分别表示召回率和准确率。最后的 $F_{lcs}$即是所说的 ROUGE-L分数。当b很大时,说明ROUGE_L分数几乎是只考虑$R_{lcs}$。
(3)代码实现
from rouge import Rouge
# 示例文本
hypothesis = "the cat was found under the bed"
reference = "the cat was under the bed"
# 创建 Rouge 对象
rouge = Rouge()
# 计算分数
scores = rouge.get_scores(hypothesis, reference)
# 这里给出ROUGE_L的结果,也可以尝试其他结果比如(ROUGE_1, ROUGE_2...)
print("ROUGE-L precision:", scores[0]["rouge-l"]["p"])
print("ROUGE-L recall:", scores[0]["rouge-l"]["r"])
print("ROUGE-L F1 score:", scores[0]["rouge-l"]["f"])
# print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
# print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
# print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
4. Perplexity
(1)介绍
Perplexity是一个在大模型评测中十分常见的评测指标,也经常用来衡量语言模型的好快,本文主要介绍这个指标在文本生成领域的应用。对于某个特定的序列,模型生成这个序列的概率越大,则其困惑度越小。
(2)计算过程
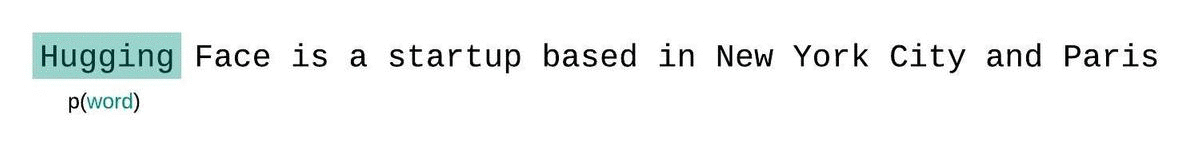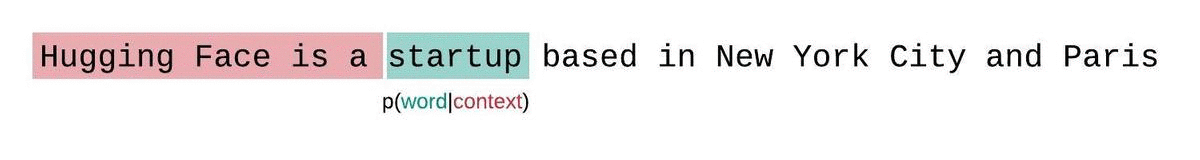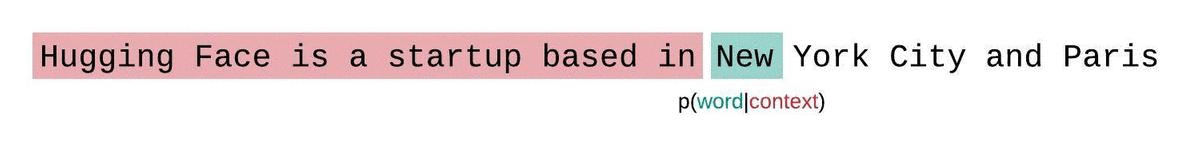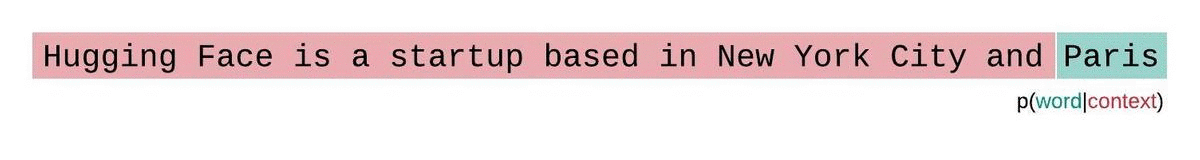
首先,对于一个给定的序列$S=W_{1},W_{2},…,W_{k}$,由于现在大部分的大语言模型是基于Decoder-only架构的,生成一个序列的时候,每个时间步的token的生成概率不是完全独立的,而是会受到前面一些token的影响,则要生成整个序列S的概率为联合概率
但是这个概率有一个问题:$p(W_{1}),P(W_{2}|W_{1}),…,P(W_{k}|W_{1},W_{2},…,W_{k-1})$这些概率都是$< 1$的,那么当句子的长度越长,那么整个$P(S)$的值必然越小,所以为了解决这个问题,可以对上面的计算公式加上几何平均,即
同时上面介绍过,生成这个序列的概率越大,则其困惑度越小,那么可以取上面这个几何平均的值的倒数作为最终的指标,最终计算公式为:
与交叉熵的关系:
log计算公式:对数公式_百度百科 (baidu.com)
(3)代码实现
import torch
from torch import Tensor
import torch.nn.functional as F
def cal_perplexity(outputs: Tensor, targets: Tensor, config=None):
"""
:param outputs: 模型输出
:param targets: 参考输出
:return: 困惑度
"""
return float(torch.exp(F.cross_entropy(outputs, targets)))
if __name__ == "__main__":
num_classes = 5
batch_size = 1
torch.manual_seed(42)
output = torch.rand(batch_size, num_classes) # 模型输出
target = torch.randint(num_classes, (batch_size,)) # 参考输出
print("PPL值为: ", cal_perplexity(output, target))
"""
PPL值为: 4.331761360168457
"""5. CIDEr
论文地址:https://arxiv.org/pdf/1411.5726.pdf
(1)介绍
CIDEr(Consensus-based Image Description Evaluation)是Vedantm 在 2015 年计算机视觉与模式识别大会上提出来的针对图像摘要问题的评价标准。首先,该指标是基于共识(Consensus)的评价标准,基本原理是通过计算待测评语句与其他人工描述句之间的相似性来评价相似性。研究者证明 CIDEr 在与人工共识的匹配度上要好于其它评价指标。其次,CIDEr基于句子层面上的,它将每个句子看做一个文档,每个参考句与候选句之间通过计算TF-IDF向量的余弦距离来度量其相似性。候选句的CIDEr分数是与所有句子计算出的分数的平均。
(2)计算过程
符号说明:
| 符号 | 含义 |
|---|---|
| $m$ | 代表候选句有m句 |
| $n$ | 一般取4。n = 1, 2, 3, 4对应n-gram的n,如1-gram,… |
| $w_n$ | 不同n-gram的权重,一般可以取1/n |
| $\mathrm{g^n(c_i)}$ | 表示句子$c_i$的n-gram的TF-IDF weight 向量 |
| $\mathrm{g^n(s_ij)}$ | 表示句子$s_ij$的n-gram的TF-IDF weight 向量 |
| $\mathrm{C}=\{\mathrm{c}_1,\mathrm{c}_2,…,\mathrm{c}_\mathrm{N}\}$ | 候选句集合(Candidates),$c_i$就是一个句子 |
| $\mathrm{S_i}=\{\mathrm{s_{i1}},\mathrm{s_{i2}},…,\mathrm{s_{im}}\}$ | 参照集(References),i表示第i个图像,m代表第几个参考句。 |
a. 计算n-gram的$CIDE_n$值
b. 计算所有n-gram的平均值
(3)代码实现
有兴趣的读者可以访问tylin/coco-caption来获取相关的代码实现。
三. 总结
本文主要讲述了文本生成任务性能评估的多个常见指标,包括BLEU、METEOR、ROUGE、Perplexity和CIDEr,这些指标为评估文本生成系统提供了全面的视角。每个指标都有其各自的侧重点和适用场景,共同构成了一个多维度的评估体系。在实际应用中,选择合适的评估指标需要根据具体任务的需求和特点来决定。此外,随着自然语言处理技术的不断进步,新的评估方法和指标也在不断涌现,为文本生成任务的性能评估提供了更多可能性。
通过本文的介绍,我们希望读者能够对文本生成任务的性能评估有一个基本的认识,并能够在自己的研究或开发工作中,有效地应用这些评估指标。
四. 参考文献
- Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Vedantam R, Lawrence Zitnick C, Parikh D. Cider: Consensus-based image description evaluation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 4566-4575.
- Perplexity of fixed-length models explained in huggingface
- Capabilities | CS324 (stanford-cs324.github.io)
- Perplexity - Wikipedia
- ROUGE — PaddleEdu documentation (paddlepedia.readthedocs.io)
- Perplexity — PaddleEdu documentation (paddlepedia.readthedocs.io)
- Perplexity (xffxff.github.io)