一. 概述
在自然语言处理(Natural Language Process)中,文本生成(Natural Language Generation)是一个重要的研究领域。NLG的想法是创建一个系统,使之能够接受输入同时输出自然语言文本,输入数据既可以是自然语言文本形式,也可以是图像或者其他形式的数据。
在Wikipedia上将自然语言生成(NLG)的定义是一种生成自然语言输出的软件过程;Ehud Reiter等人将自然语言生成(NLG)定义为是一种用于构建能够产生文本的软件系统的技术,这些系统可以用英语和其他人类语言生成解释、摘要、叙述等文本;万小军教授等将这个概念扩展为根据给定的输入数据(例如报表数据、视觉信息、文本素材等)自动生成高质量的不同类型自然语言语句或篇章(例如标题、摘要、故事、诗歌等)。
Natural language generation (NLG) is a software process that produces natural language output. A widely-cited survey of NLG methods describes NLG as “the subfield of artificial intelligence and computational linguistics that is concerned with the construction of computer systems than can produce understandable texts in English or other human languages from some underlying non-linguistic representation of information”.
二. 文本生成任务分类
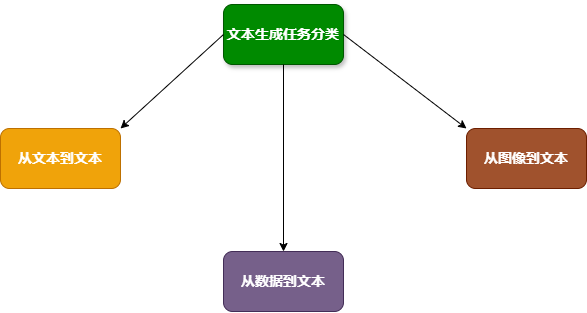
由于在文本生成领域并没有对文本生成任务有一个明确的分类标准,本文按照输入数据的类型将文本生成任务分为三类:
- 从文本到文本的生成任务
- 从数据到文本的生成任务
- 从图像到文本的生成任务
三. 常见的文本生成任务
1. 文本摘要(Text Summarization)
文本摘要广泛应用于多种任务和场景中,按照任务进行划分,可以将文本摘要分为单文档摘要、多文档摘要、对话摘要等。单文档摘要是最基本的摘要任务,给定一篇文档作为输入,模型输出它的核心内容,且长度明显短于输入文档。多文档摘要是对同一主题下的多个文档提炼主要信息并输出摘要。结合具体案例来看,比如说对于某新闻事件,媒体对其进行了一系列的报道,那么对这些相关性较强的多文档提炼出一个覆盖性强、形式简短的摘要便具有重要的意义。对话摘要是为多种类型的对话生成摘要,包括会议、通话记录、在线聊天和客服对话等场景。相比前文提过的新闻摘要等,对话摘要很难直接从现有的内容中获取,因此相对来说开展对话摘要任务是更加困难的。
2.机器翻译(Machine Translation)
机器翻译是借计算机技术自动地将一种自然语言文本(源语言)翻译成另一种自然语言文本(目标语言)。机器翻译的类型可以大致分成三类:基于规则的机器翻译(RBMT),基于统计的机器翻译(SMT),基于神经网络的机器翻译(NMT)。
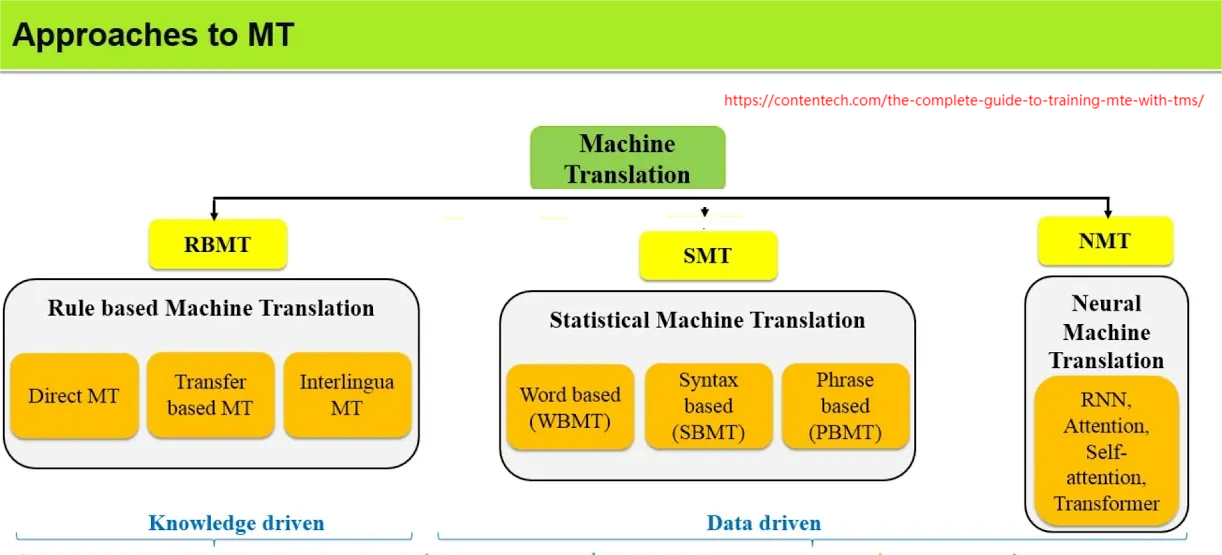
基于规则的机器翻译(RBMT)是一种利用语言学规则将源语言文本转换为目标语言文本的技术。这些规则通常由语言学家手工编写,覆盖了语法、词汇和其他语言相关的特性。在很长一段时间里(20 世纪 50 年代到 80 年代),机器翻译都是通过研究源语言与目标语言的语言学信息来做的,也就是基于词典和语法生成翻译,所以可以看出,这种类型的机器翻译实际上与专家的掌握的知识及经验是密不可分的。
基于统计的机器翻译 (SMT) 是一种利用统计模型从大量双语文本数据中学习如何将源语言翻译为目标语言的技术。与依赖语言学家手工编写语言学规则的RBMT翻译方法不同,SMT会自动从提供的大量文本数据中提取和学习翻译规则和模式。综合来说,这种机器翻译方法不再简单依靠专家知识,而是由数据驱动,所以SMT的表现比 RBMT 更好,并且在 1980 年代到 2000 年代之间主宰了机器翻译领域。
基于神经网络的机器翻译(NMT)是利用了深度学习技术(Deep Learning),特别是循环神经网络(RNN)、长短时记忆网络(LSTM)以及Google提出的Transformer架构,以端到端的方式进行翻译。它直接从源语言到目标语言的句子或序列进行映射,不需要复杂的特性工程或中间步骤。与传统的基于统计的机器翻译(SMT)不同,NMT的目标是建立一个神经网络系统,可以共同调整以最大化翻译性能。同时用于神经机器翻译的模型经常属于编码器-解码器这种结构,这种结构将源句子编码成固定长度的张量,最终解码器从该张量生成翻译文本。
3. 问答系统(Question Answering)
问答(QA)是信息检索(IR)和自然语言处理(NLP)领域中的一门计算机科学学科,通常情况下,问答系统是指能够以自然语言文本回答提问者的问题的系统,而且被广泛认为是下一代智能搜索引擎的核心特点之一。同时,随着多模态知识图谱、多模态预训练模型的不断发展,广义上的问答系统可以分为以下三种类别:专用问答系统、通用问答系统和多模态问答系统。更详细的内容可以阅读参考资料。
4. 图片说明(Image Captioning)
什么是图片说明(Image Captioning)呢?从字面意义上理解,就是对图片进行描述,它是一个融合计算机视觉(CV)、自然语言处理(NLP)和机器学习(ML)的综合性任务。类似于前文提到过的机器翻译,可以理解为这里的源语就是图片,图片说明的任务就是要将一张图片翻译为一段描述这张图片的文本。
5. 开放式文本生成(Open-Ended Text Generation)

开放式文本生成(OETG)是指根据先前的上下文提示生成新的文本,以确保最终输出连贯且流畅。通俗一点来讲,就是根据已有的文本进行续写句子。开放式文本生成(OETG)的应用范围十分广泛,包括故事生成(Story generation),对话生成(Dialogue generation)等。同时应当注意的是,在句子续写任务上模型有可能会出现续写的句子在语义上和逻辑上显得文理不通的问题。
四. 参考资料
- 闫悦,郭晓然,王铁君,饶强,王铠杰.问答系统研究综述.计算机系统应用,2023,32(8):1–18. http://www.c-s-a.org.cn/1003-3254/9208.html
- Becker J, Wahle J P, Gipp B, et al. Text Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges[J]. arXiv preprint arXiv:2405.15604, 2024.